 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Agent Memory in Contextual Intent
Jan 15, 2026Deploying large language models in long-horizon, goal-oriented interactions remains challenging because similar entities and facts recur under different latent goals and constraints, causing memory systems to retrieve context-mismatched evidence. We propose STITCH (Structured Intent Tracking in Contextual History), an agentic memory system that indexes each trajectory step with a structured retrieval cue, contextual intent, and retrieves history by matching the current step's intent. Contextual intent provides compact signals that disambiguate repeated mentions and reduce interference: (1) the current latent goal defining a thematic segment, (2) the action type, and (3) the salient entity types anchoring which attributes matter. During inference, STITCH filters and prioritizes memory snippets by intent compatibility, suppressing semantically similar but context-incompatible history. For evaluation, we introduce CAME-Bench, a benchmark for context-aware retrieval in realistic, dynamic, goal-oriented trajectories. Across CAME-Bench and LongMemEval, STITCH achieves state-of-the-art performance, outperforming the strongest baseline by 35.6%, with the largest gains as trajectory length increases. Our analysis shows that intent indexing substantially reduces retrieval noise, supporting intent-aware memory for robust long-horizon reasoning.
Facial Affect Recognition based on Transformer Encoder and Audiovisual Fusion for the ABAW5 Challenge
Mar 20, 2023In this paper, we present our solutions for the 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW), which includes four sub-challenges of Valence-Arousal (VA) Estimation, Expression (Expr) Classification, Action Unit (AU) Detection and Emotional Reaction Intensity (ERI) Estimation. The 5th ABAW competition focuses on facial affect recognition utilizing different modalities and datasets. In our work, we extract powerful audio and visual features using a large number of sota models. These features are fused by Transformer Encoder and TEMMA. Besides, to avoid the possible impact of large dimensional differences between various features, we design an Affine Module to align different features to the same dimension. Extensive experiments demonstrate that the superiority of the proposed method. For the VA Estimation sub-challenge, our method obtains the mean Concordance Correlation Coefficient (CCC) of 0.6066. For the Expression Classification sub-challenge, the average F1 Score is 0.4055. For the AU Detection sub-challenge, the average F1 Score is 0.5296. For the Emotional Reaction Intensity Estimation sub-challenge, the average pearson's correlations coefficient on the validation set is 0.3968. All of the results of four sub-challenges outperform the baseline with a large margin.
Hybrid Multimodal Feature Extraction, Mining and Fusion for Sentiment Analysis
Aug 12, 2022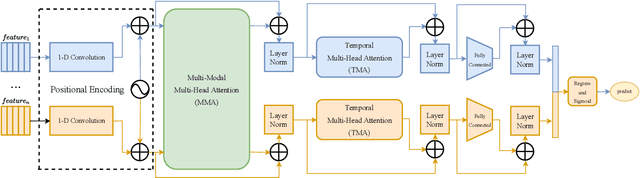
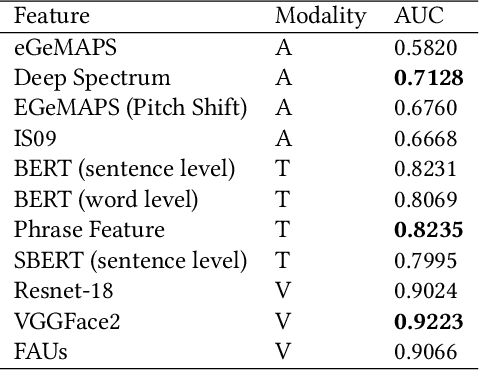
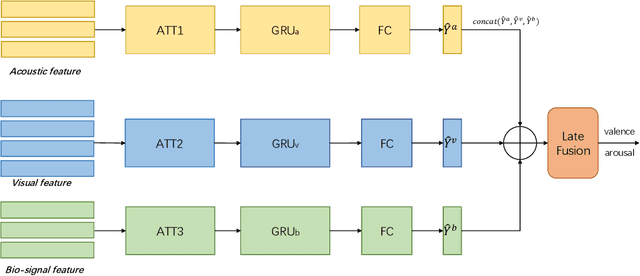
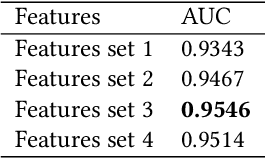
In this paper, we present our solutions for the Multimodal Sentiment Analysis Challenge (MuSe) 2022, which includes MuSe-Humor, MuSe-Reaction and MuSe-Stress Sub-challenges. The MuSe 2022 focuses on humor detection, emotional reactions and multimodal emotional stress utilizing different modalities and data sets. In our work, different kinds of multimodal features are extracted, including acoustic, visual, text and biological features. These features are fused by TEMMA and GRU with self-attention mechanism frameworks. In this paper, 1) several new audio features, facial expression features and paragraph-level text embeddings are extracted for accuracy improvement. 2) we substantially improve the accuracy and reliability of multimodal sentiment prediction by mining and blending the multimodal features. 3) effective data augmentation strategies are applied in model training to alleviate the problem of sample imbalance and prevent the model from learning biased subject characters. For the MuSe-Humor sub-challenge, our model obtains the AUC score of 0.8932. For the MuSe-Reaction sub-challenge, the Pearson's Correlations Coefficient of our approach on the test set is 0.3879, which outperforms all other participants. For the MuSe-Stress sub-challenge, our approach outperforms the baseline in both arousal and valence on the test dataset, reaching a final combined result of 0.5151.